
Транслит для заголовков Yoast Table Of Content

Содержание
Обычно для улучшения SEO показателей используется "содержание" статьи. Этот блок генерируется из заголовков (H1, H2, H3 и т.д.) статьи. Для этого используются разные WordPress плагины такие как Table of Contents Plus или Easy Table of Contents.
Лично я использую Yoast Table of Contents в редакторе Gutenberg
Выглядет это следующим образом:
Преимущество данного способа заключается в том, что можно добавлять содержимое в любом месте на странице, например после изображения статьи или в конце статьи.
Проблема якорных ссылок на кириллице
По умолчанию Yoast генерирует id якорных ссылок из названия заголовка, поэтому ссылка и якорь будут на кириллице. Это не всегда хорошо! Например если вы захотите подключить турбо страницы от Яндекс, то валидатор будет ругаться на такие якорные ссылки следующим сообщением:
Якорь, на который указывает ссылка, отсутствует или указан у неподдерживаемого элемента. В качестве якоря можно использовать контент в виде аккордеона или заголовок h1–h6
Транслит якорных ссылок для Yoast Table of Contents
Чтобы исправить эту проблему достаточно добавить в functions.php этот код:
add_filter('the_content', 'toc_translit_link');
function toc_translit_link($content) {
$translit = [
'А' => 'A', 'Б' => 'B', 'В' => 'V', 'Г' => 'G', 'Ѓ' => 'G',
'Ґ' => 'G', 'Д' => 'D', 'Е' => 'E', 'Ё' => 'YO', 'Є' => 'YE',
'Ж' => 'ZH', 'З' => 'Z', 'Ѕ' => 'Z', 'И' => 'I', 'Й' => 'J',
'Ј' => 'J', 'І' => 'I', 'Ї' => 'YI', 'К' => 'K', 'Ќ' => 'K',
'Л' => 'L', 'Љ' => 'L', 'М' => 'M', 'Н' => 'N', 'Њ' => 'N',
'О' => 'O', 'П' => 'P', 'Р' => 'R', 'С' => 'S', 'Т' => 'T',
'У' => 'U', 'Ў' => 'U', 'Ф' => 'F', 'Х' => 'H', 'Ц' => 'TS',
'Ч' => 'CH', 'Џ' => 'DH', 'Ш' => 'SH', 'Щ' => 'SHH', 'Ъ' => '',
'Ы' => 'Y', 'Ь' => '', 'Э' => 'E', 'Ю' => 'YU', 'Я' => 'YA',
'а' => 'a', 'б' => 'b', 'в' => 'v', 'г' => 'g', 'ѓ' => 'g',
'ґ' => 'g', 'д' => 'd', 'е' => 'e', 'ё' => 'yo', 'є' => 'ye',
'ж' => 'zh', 'з' => 'z', 'ѕ' => 'z', 'и' => 'i', 'й' => 'j',
'ј' => 'j', 'і' => 'i', 'ї' => 'yi', 'к' => 'k', 'ќ' => 'k',
'л' => 'l', 'љ' => 'l', 'м' => 'm', 'н' => 'n', 'њ' => 'n',
'о' => 'o', 'п' => 'p', 'р' => 'r', 'с' => 's', 'т' => 't',
'у' => 'u', 'ў' => 'u', 'ф' => 'f', 'х' => 'h', 'ц' => 'ts',
'ч' => 'ch', 'џ' => 'dh', 'ш' => 'sh', 'щ' => 'shh', 'ъ' => '',
'ы' => 'y', 'ь' => '', 'э' => 'e', 'ю' => 'yu', 'я' => 'ya'
];
$content = preg_replace_callback("/<(a|h)(.*?)(href|id)=('|\")(h|#h)(-.*?)('|\")(.*?)>/i", function ($match) use ($translit) {
return "<" . $match[1] . $match[2] . "$match[3]" . "=" . $match[4] . $match[5] . strtr($match[6], $translit) . $match[7] . $match[8] . ">";
}, $content);
return $content;
}
Разбор кода
Из кода выше видно, что для преобразования кириллицы в латиницу нужно использовать фильтр the_content. Функция the_content() выводит содержимое текущего поста (записи, страницы или произвольного типа поста) в цикле. То-есть мы берем весь контент поста и с помощью Regex ищем нужные совпадения.
https://regex101.com/r/eklqpk/1
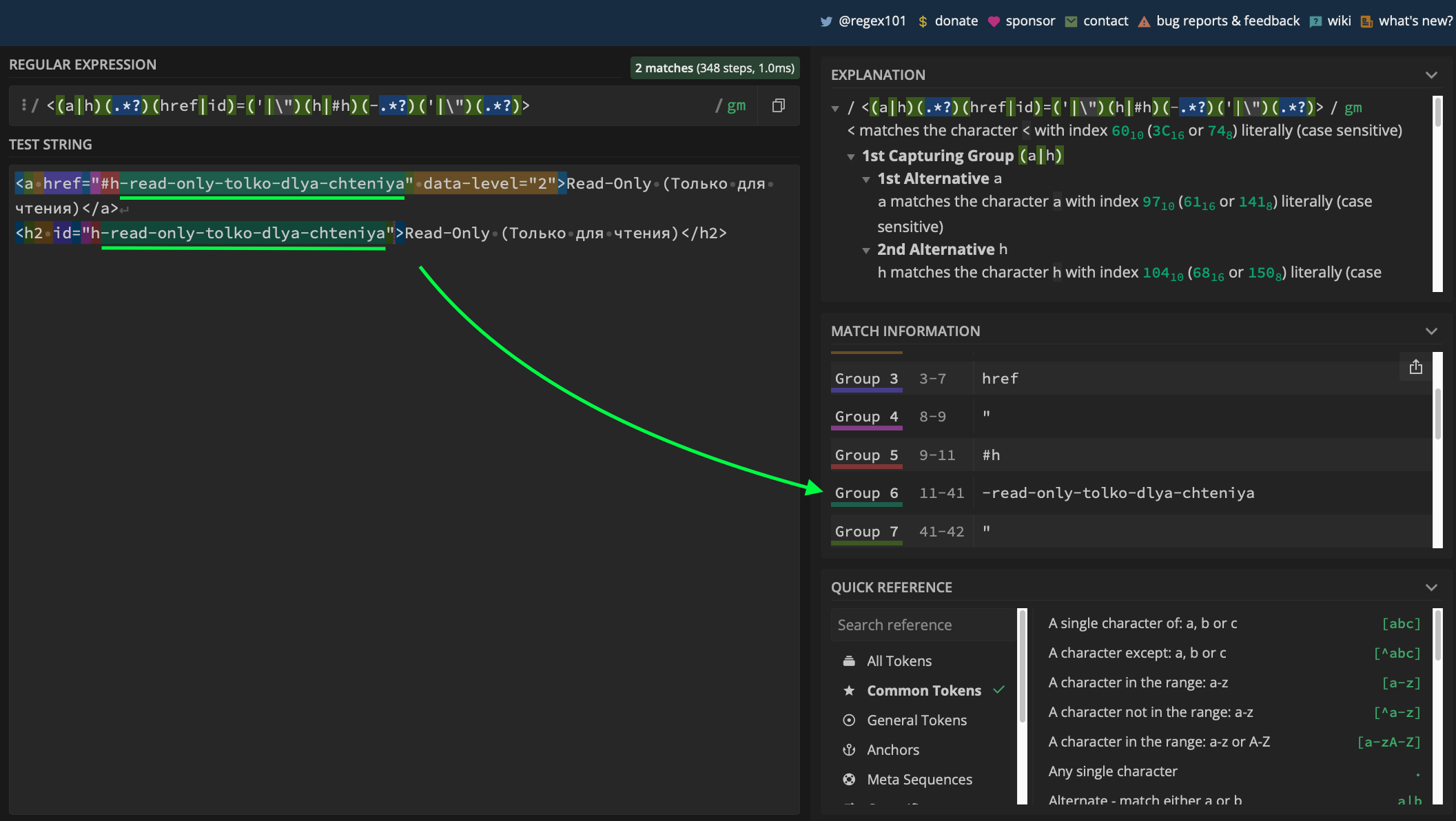
Массив $translit нужен для замены символов. Используя функцию strtr() сделаем замены, тем самым и сгенерируем нужные нам ссылки на транслите.
Но перед заменой символов нужно найти строки (якоря и айдишники)
Для поиска и замены функция preg_replace нам не подходит, так как мы должны поменять в определенной группе совпадений русские буквы на латинские с помощью функции strtr.
По этому мы используем preg_replace_callback, которая позволяет манипулировать с совпадением.
Из скриншота выше видно, что нам нужно сделать замену в двух местах, в самой ссылке и якоре. После замены нужных данных мы возвращаем сгенерированный контент:
return $content;